Predicting Hotel Booking Cancellation
- Ajay Reddy
- Dec 8, 2021
- 3 min read

Updated: Dec 13, 2021
Aim of this project
is to help the company in predicting which customer will cancel the booking.
We have booking details for a city hotel and a resort hotel, such as when the booking was made, length of stay, arrival date, number of guests, available parking spaces and other parameters.
First, we will focus on Exploratory Data Analysis and then move on to the prediction approach.
Loading the data:

Data Preprocessing:
The data can have many irrelevant and missing parts. To handle this part, data cleaning is done. It involves handling of missing data, noisy data etc.
In the given dataset there are many null values which are found by the method isnull(). We then performed certain data preprocessing steps(such as ignoring the column, replacing null with 0) to avoid those null values.
Exploratory Data Analysis:
After cleaning the data, I performed exploratory data analysis as it is a critical process of performing initial investigations on data so as to discover patterns, to spot anomalies, to test hypothesis and to check assumptions with the help of summary statistics and graphical representations.
Below are few bar graphs that gives us the information about:
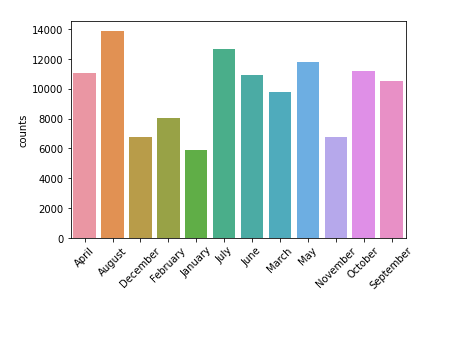
The total number of guests per month. Here we can see in the months of May, July and August more number of guests arrive.

Bar graph showing number of guests arrived vs guests who cancelled their reservation.

Bar graph showing the data of cancelled reservations and their refund status. As we can see most of the cancellations are non refundable.
Split the dataset:
To train any machine learning model irrespective what type of dataset is being used you have to split the dataset into training data and testing data. Here the data is split using the ‘train_test_split’ library from sklearn into 70% training and 30 % testing data.

Feature scaling:
The reason I'm performing feature scaling is, the algorithm just sees number — if there is a vast difference in the range say few ranging in thousands and few ranging in the tens, and it makes the underlying assumption that higher ranging numbers have superiority of some sort. So these more significant number starts playing a more decisive role while training the model.
Scaling can make a difference between a weak machine learning model and a better one.

Training and testing the model using :
In this step we train the data on various machine learning models individually and then predict() function is used to predict the values for the test set and the values are stored into a variable.
1. Logistic Regression:
This is an inference and classification model used to assign observations to a binary set of classes by returning a probability value.

Accuracy achieved - 81.48%
2. Decision Tree Classifier:
The decision tree acquires knowledge in the form of a tree, which can also be rewritten as a set of discrete rules to make it easier to understand. The main advantage of the decision tree classifier is its ability to using different feature subsets and decision rules at different stages of classification.

Accuracy achieved - 93.37%
3. Random Forest Classifier:
The algorithm randomly selects observations (bootstrap samples) and a subset of the features from the train data and constructs a decision tree for every sample. From each decision tree, it will get the prediction results and based on the majority votes of predictions, it averages the results to predict the final output. Since random forests are very flexible, we expect to get a high accuracy.

Accuracy achieved - 93.86%
4. KNeighbours Classifier:
A k-nearest-neighbor algorithm, often abbreviated k-nn, is an approach to data classification that estimates how likely a data point is to be a member of one group or the other depending on what group the data points nearest to it are in.
The k-nearest-neighbor is an example of a "lazy learner" algorithm, meaning that it does not build a model using the training set until a query of the data set is performed.

Accuracy achieved - 86%
5. AdaBoost Classifier:
AdaBoost algorithm, short for Adaptive Boosting, is a Boosting technique used as an Ensemble Method in Machine Learning. It is called Adaptive Boosting as the weights are re-assigned to each instance, with higher weights assigned to incorrectly classified instances. Boosting is used to reduce bias as well as variance for supervised learning.

Accuracy achieved - 82.06%
Comparing the models:
Based on the scores above a bar plot is drawn to compare the accuracy of the all the models.
From the graph it is evident that "Random Forest Classifer" predicted with higher accuracy compared to other models.

My Contributions:
Treating the missing values in the data with the least significant column to be dropped and filling the other null values with either mean or most common value.
Had done exploratory data analysis on the dataset and drawn insights and visualised them using libraries.
Had trained the data on 5 different models and compared those results to find out the best model for our data.



Comments