Sentiment Analysis using Naive Bayes Classifier
- Ajay Reddy
- Dec 1, 2021
- 2 min read

Updated: Dec 7, 2021
IMDb movie reviews classification into positive and negative sentiments.
This blog post speaks about the Naive Bayes classifier which is a simple classifier that classifies based on probabilities of events. It is the applied commonly to text classification. Though it is a simple algorithm, it performs well in many text classification problems.
Bayes Theorem:
Naive Bayes, more technically referred to as the Posterior Probability, updates the prior belief of an event given new information. The result is the probability of the class occuring given the new data.
The classification model could handle binary and multiple classifications.
When predicting a class, the model calculates the posterior probability for all classes and selects the largest posterior probability as the predicted class.

In this blog we perform sentiment analysis using Naive Bayes model. The data set used here is the IMDb data set which is available at Sentiment Labelled Sentences Data Set | Kaggle. This dataset consists of various movie reviews and sentiments labelling those reviews as 0 and 1 for negative reviews and positive reviews respectively.
Load the dataset:
Firs we load the data set into the program and convert the txt file to csv file. This dataset consists of 362 negative reviews and 386 positive reviews. As the reviews have punctuation in it, we need to clean the data and remove the punctuation.
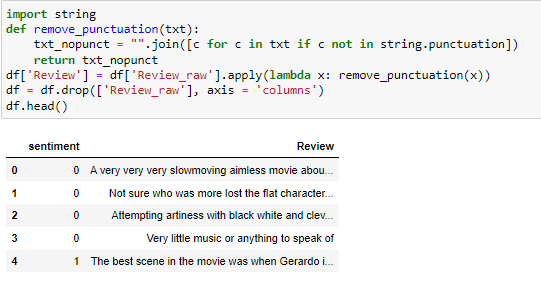
Split the data:
After cleaning the data we split the data into train, dev and test sets. Here we split the data 80% to test, 10% to dev and 10% to test sets.

Build the vocabulary:
Here we count the occurrence of the words in the data and later we omit the words whose occurrence is less than 5 times. We do this because these words are not significant in predicting the class of the sentiment.

Accuracy on dev dataset:
After building the dataset we then calculate the accuracy of the dev dataset.

Cross Validation:
We then conduct 5 fold cross validation using the development dataset and divide it into 5 parts where 4 parts are used for training and 1 part is used for testing. This algorithm is iterated 5 times as 5 different parts are used as test set throughout the algorithm.
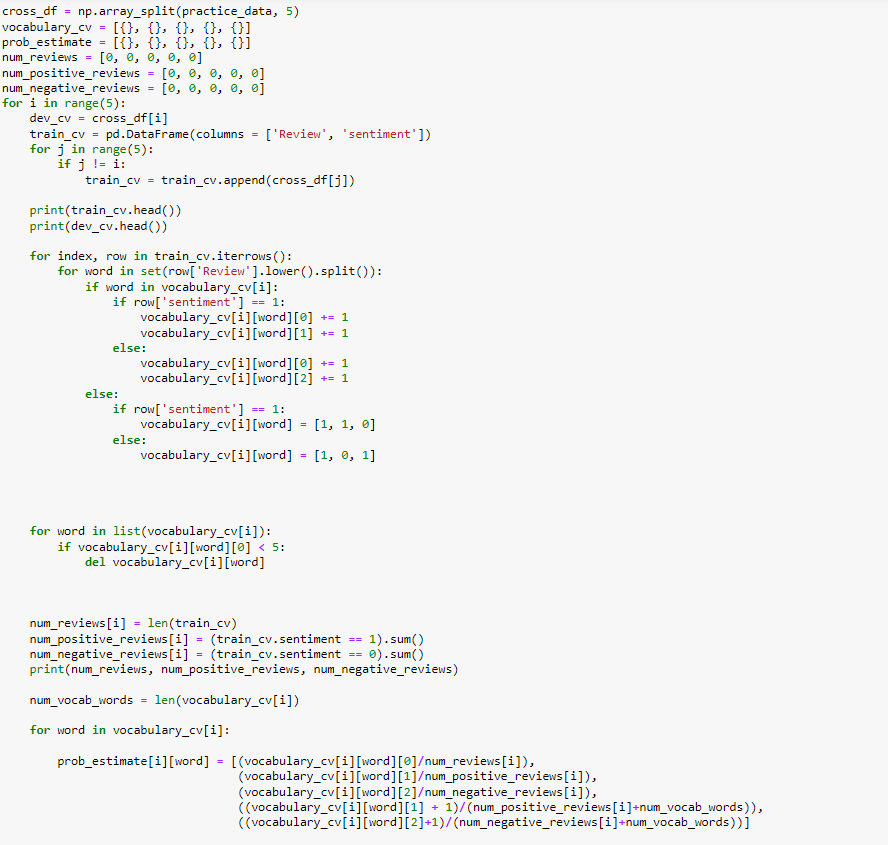
Smoothing:
Laplace smoothing is a smoothing technique that handles the problem of zero probability in Naïve Bayes. Using Laplace smoothing, we can represent P(w’|positive) as

Here,
alpha represents the smoothing parameter,
K represents the number of dimensions (features) in the data, and
N represents the number of reviews with y=positive


Testing the model:
After performing smoothing, we finally test the model we built using our test dataset. Here the accuracy achieved is 68%.

Final Accuracy: 65%
My contribution:
Using string library for removing punctuation istead of hard coding the values to remove. For the initial split of the data I took 60% of the data for train set, remaining 40% for dev and test set. In this experiment it has shown accuracy of 62% only. After changing the split ratio to 80% for train set and the remaining for dev and test set the accuracy has increased to 68%.
Using smoothing technique for the classifier
Challenges faced:
Building the Naïve Bayes model without using scikit library.
Building vocabulary to find probabilities of the words and implenting laplace smoothing : referenced links helped me to implement it without library.



Comments